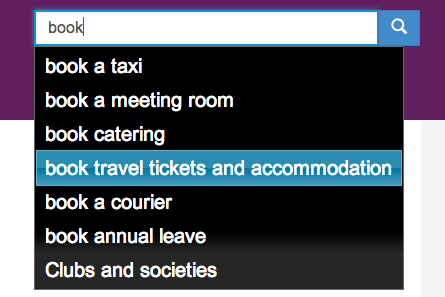
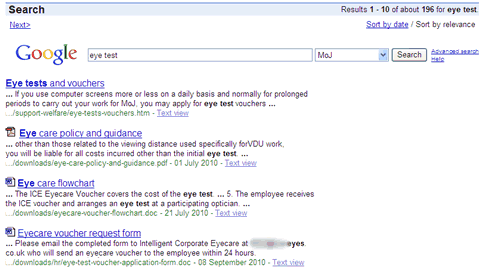
I recently posted my comparison of search results across 2 similar intranets. In this post, I use the same set of 21 search phrases to test the GovIntranet predictive search feature on the recently released Northern Ireland Office intranet. Some of the search tasks are not really applicable to this department but I have included them for completeness.